Эвиденциальность и перфект в нахско-дагестанских языках
Репозиторий dissertation_evidentiality содержит данные, собранные мной для кандидатской диссертации по теме Эвиденциальность как часть видо-временной системы в нахско-дагестанских языках (2015–2019). Полный текст диссертации (на русском языке), автореферат (на русском) и резюме (на английском) доступны здесь.
Настоящая страница представляет данные в виде таблиц с поисковыми строками, и интерактивных карт.
В репозитории можно найти следующие данные:
- Таблицы с данными о разных эвиденциальных показателях
- Аннотированные анкеты
- Аннотированные нарративные данные
- Интерактивные карты
Страница была создана с RMarkdown в RStudio (RStudio Team 2018), с помощью следующих пакетов: tidyverse (Wickham 2017) для манипуляции данных, lingtypology (Moroz 2017) для карт, ggpubr (Kassambara 2018) для особых графиков и DT (Xie, Cheng, and Tan 2019) для таблиц с поиском.
Карты, сделанные в lingtypology пользуются картамы из библиотеки leaflet. Конкретный источник той или иной визуализации (напр. Esri или OpenStreetMap) на каждой карте упоминается внизу.
Спасибо моему учителю по R — Г.А. Морозу.
Самира Ферхеес | Версия: 2020-05-12 | jh.verhees at gmail
Введение
Показатели эвиденциальности указывают на то, как человек знает о том, о чем он говорит, например, из личного опыта, из умозаключения, или с чужих слов.
На Кавказе данная категория обычно выражается перфектной формой глагола, обозначающей, что говорящий не был свидетелем события. Другие способы выражения эвиденциальности включают в себя частицы и специализированные вспомогательные глаголы (см. обзор эвиденциальности в нахско-дагестанских языках (Forker 2018)).
Диссертация сосредоточилась на вопрос о том, насколько грамматикализована эвиденциальность как значение перфекта в языках нахско-дагестанской семьи, и дополнительно: вероятно ли, что оно появилось под влиянием местных тюркских языков. Помимо сравнительного исследования форм и их функции были созданы карты для визуализации распространения определенных признаков.
Данные
Показатели эвиденциальности
Сравнение формы и функции эвиденциальных показателей основано на грамматиках и статьях о 44 идиома и 32 языка (включая все нахско-дагестанские языки, которые традиционно различаются, три тюркских языка и несколько дополнительных идиомов). Полный список источников можно найти в файле bibliography.bib в настоящем репозитории.
Перфект
- Во всех нахско-дагестанских языках имеется 1-4 формы, похожие на перфект1
- Многие из них имеют эвиденциальное значение косвенной засвидетельствованности
- В чеченском и цахурском языках вместо перфекта используется специализированный вспомогательный глагол для выражения косвенной засвидетельствованности2
Перфекты имеют похожую структуру по всем ветвям семьи: чаще всего они являются аналитическими формами на основе конверба и копулы настоящего времени.
##
## auxiliary copula no auxiliary predicative marker
## converb 3 26 8 8
## participle 1 8 4 6
## stem 0 2 0 0
## unclear 0 0 4 0Перфект одновременно может выразить видо-временное значение и эвиденциальность, когда говорящий делает вывод (т.е. умозаключение) о случившемся в прошлом событии на основе какого-нибудь последствия в момент речи.
Когда перфект достаточно грамматикализован как показатель эвиденциальности, он может указать на незасвидетельствованное событие без результата или последствия на момент речи. Важно отметить, что одна форма может выступать в качестве прошедшего “заглазного” в одних контекстах (в основном нарративные цепочки), но сохраняя более прототипичные перфектые функции (т.е. значения текущей релевантности) в других.
В некоторых языках, общее прошедшее по контрасту с пефректом как показателем косвенной эвиденциальности (прошедшее заглазное) считается грамматикализованными показателем прямой эвиденциальности (прошедшее очевидное). Тем не менее, данные форм также употребляются в контексте незасвидетельствованных событиях — скорее всего они явлются нейтральными формами, которые приобретают оттенок личного свидетельства в определенных контекстах.
В таблице ниже можно найти все формы, рассмотренные нами. Среди них все перфекты, или точнее: “перфектоиды”: формы, похожие на перфект как кросс-лингвистическую категорию, но для которых значение текущей релевантности может быть не самой главной функцией формы. Типология перфекта и наши решении классификации обсуждаются подробнее в диссертации.
Таблица: Перфектоиды
Клитики
В нахско-дагестанских языках, специализированные эвиденциальные морфемы обычно появляются в форме клитических частиц. Некоторые из них присоединяются к финитным формам глагола, а другие являются фокусными частицами, которые присоединяются к разным составляющим (хотя по умолчанию, они находятся на глаголе). Эти клитики часто восходят к глаголам речи. В некоторых языках остывшие формы глагола или спрягаемые глаголы употребляются как клитики. Большинство клитик маркируют репортатив, или информацию с чужих слов. Частицы инферентива и косвенной засвидетельствованности отмечены только в двух языках.
Не все клитики для передачи чужой речи являются показателями эвиденциальности. Многие из них — на самом деле цитатные (или “квотативные”) частицы, которые указывают на границу цитаты, а не на источник информации. В нахско-дагестанских языках одна морфема может выполнять функции квотатива и репортатива. Репортатив указывает на информацию с чужих слов. В таблице ниже помечены как “эвиденциальный” (evidential) те клитики, про которые известно, что у них есть репортативная функция.
Данные про клитики страдают дескриптивными лажами. Частицы являются плохо описуемой категорией, и их классификация в разных источниках — сложно сопоставимо.
Таблица: клитики для передачи чужой речи и умозаключения
Анкеты
Цель проведенных анкет заключалась в том, чтобы проверить в каких идиомах перфект имеет эвиденциальное употребление, и чтобы установить грамматический статус данной функции, сравнивая употребление разных форм прошедшего времени в ограниченном контексте у разных носителй.
- Маленькая анкета про эвиденциальность: короткая анкета, нацелена на элицитацию эвиденциальных форм
- Анкета про перфект: анкета для элицитации разных функций перфекта (Dahl 2000, 800–818)
- Анкета для нарративов: расширение “нарративных вопросов” анкеты про перфект
Заполненные анкеты доступны в виде таблиц, содержащих следующую информацию:
- дискурсивный контекст
- предложение для перевода
- translat_original – перевод в кириллице
- translit_morph – перевод в транскрипции с морфемным членением
- глоссы
- перевод перевода – для тех случаев, когда перевод сильно отличается от стимула
- target_verb – глагол из исходного предложения, форма которого интересует нас
- target_translation – перевод того глагола
- ожидаемый ответ
- действительный ответ
- метаданные: идиом, язык, носитель, род, год рождения, дата элицитации
Маленькая анкета про эвиденциальность
Маленькая анкета про эвиденциальность состоит из 11 вопросов. Некоторые из них предлагают несколько предложений на перевод.3 Таблица ниже показывает количество предложений, элицитированных от каждого носителя, вместе с их языком и идиомом. Данная анкета была назначена для предварительного исследования.4 Некоторые результаты рутульского языка обсуждаются в (Ferxees 2017).
## # A tibble: 6 x 4
## # Groups: language, idiom [4]
## language idiom speaker sentences
## <chr> <chr> <dbl> <int>
## 1 Andi Zilo 1 4
## 2 Andi Zilo 2 16
## 3 Avar ? 1 23
## 4 Dargwa Itsari 1 11
## 5 Rutul Kina 1 12
## 6 Rutul Kina 2 8Анкета про перфект
Анкета про перфект была заполнена с двумя носителями аварского языка (хунзахский диалект) и с двумя носителям андийского языка (рикванинский и зиловский диалекты). Согласно методолгии, одного носителя достаточно, но большее количество носителей увеличивает достоверность результата (Dahl 2000, 800).
Носители ответили по-разному, что может отражать возрастную, гендерную, или (в случае андийского языка) диалектную разницу. Один носитель аварского языка избежал употребление перфектов (см. график нижу), что возможно является последствием неуверенности в собственном владении языка.
(Переменная “not p” в графике покрывает общее прошедшее (в данном случае: аорист) и производные из него формы, например, плюсквамперфект со вспомогательным глаголом в форме аориста, напротив плюсквамперфекта со вспомогательным глаголом в форме перфекта. Категория “other” включает в себя все кроме перфекта или аориста.)
Рисунок: Формы, используемые в контекстах где ожидался бы перфект
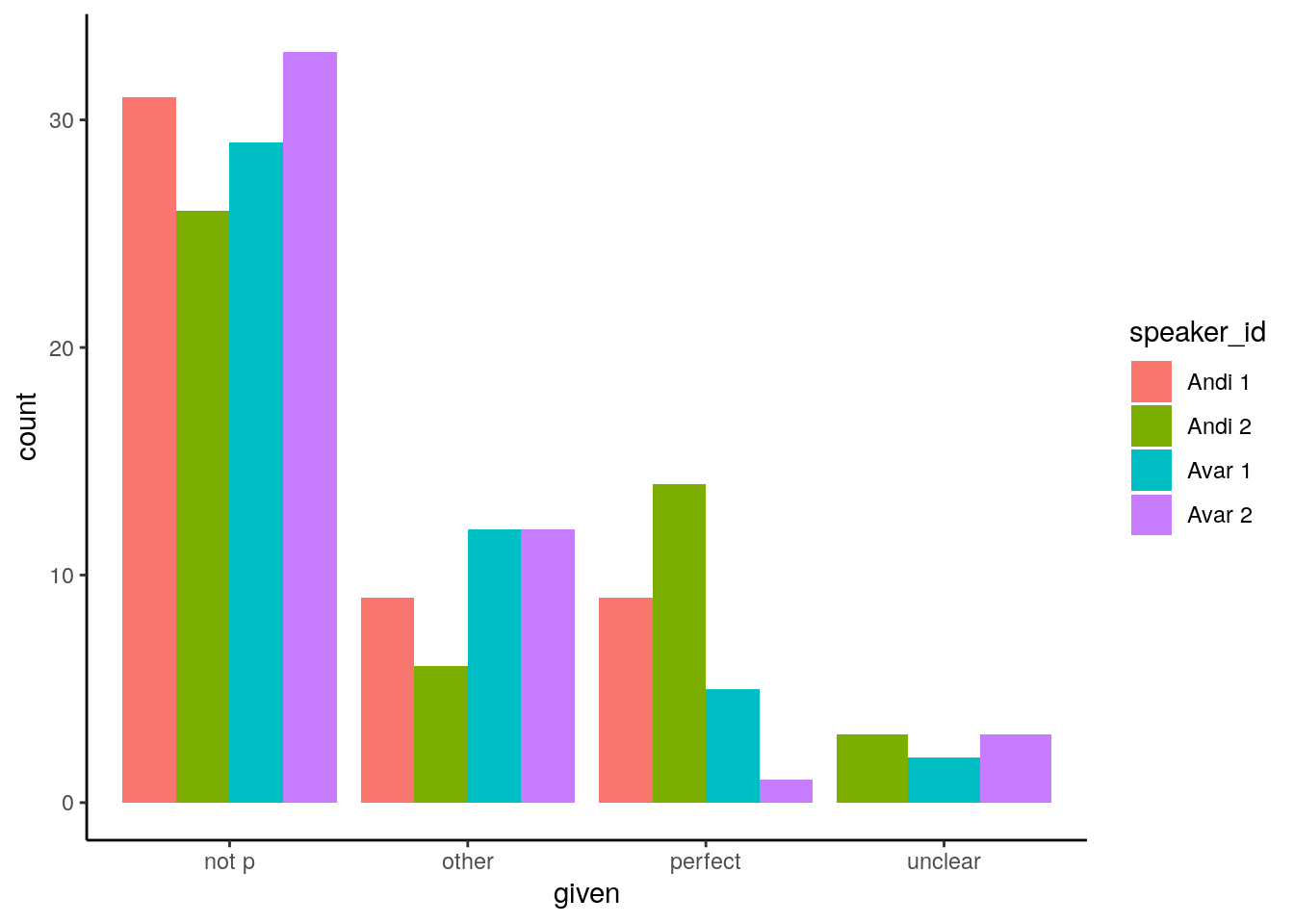
Все четыре носителя использовали перфект в контексте рассказа про незасвидетельствованные события. В связи с этим, мы решили повторить похожий эксперимент с другой выборкой носителей (см. ниже).
Анкета для нарративов
Анкета про перфект, которая обсуждалась выше, содержит несколько вопросов, направленных на элицитацию похожих, коротких рассказов. В каждом рассказе происходит маленькое изменения в плане темпоральной или эвиденциальной перспективе.
Эти вопросы оказались очень эффективными для элицитации использования перфекта в качестве показателя косвенной засвидетельствованности. Поэтому мы решили создать отдельную анкету для элицитации двух похожих нарративов, с разными эвиденциальными перспективами. Первый нарратив пересказывает историю про бабушку носителя (косвенная засвидетельствованность), а второй нарратив передает ту же историю как воспоминание из личного опыта (прямая засвидетельствованность).
Здесь можно прочитать тест и его английский перевод.
Данный эксперимент был проведен с носителями разных диалектов андийского языка, в основном рикванинский и зиловский диалекты.
## # A tibble: 4 x 3
## # Groups: language [1]
## language idiom speakers
## <chr> <chr> <int>
## 1 Andi Muni 1
## 2 Andi Rikvani 5
## 3 Andi Rushukha 1
## 4 Andi Zilo 6Больше всего носители использовали аорист (наименее маркированное прошедшее время) и перфект. Рисунок ниже показывает, что ожидаемая корреляция между используемой формой и эвиденицальной перспективой подтверждается: аорист более характерен для контекста личной засвидетельствованности, а перфект более частотен в заглазном контексте.
Рисунок: используемые формы в анкете для нарративов
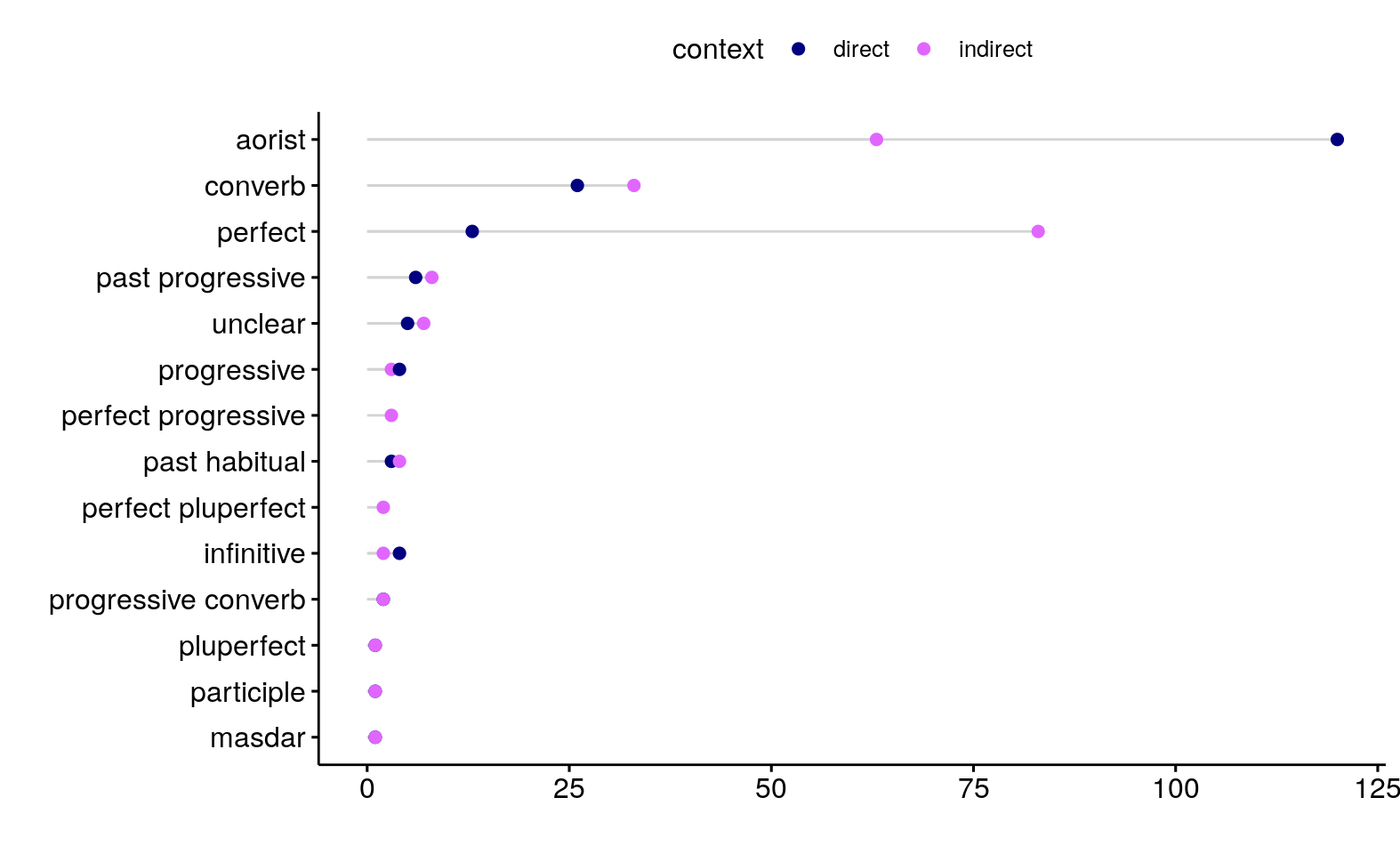
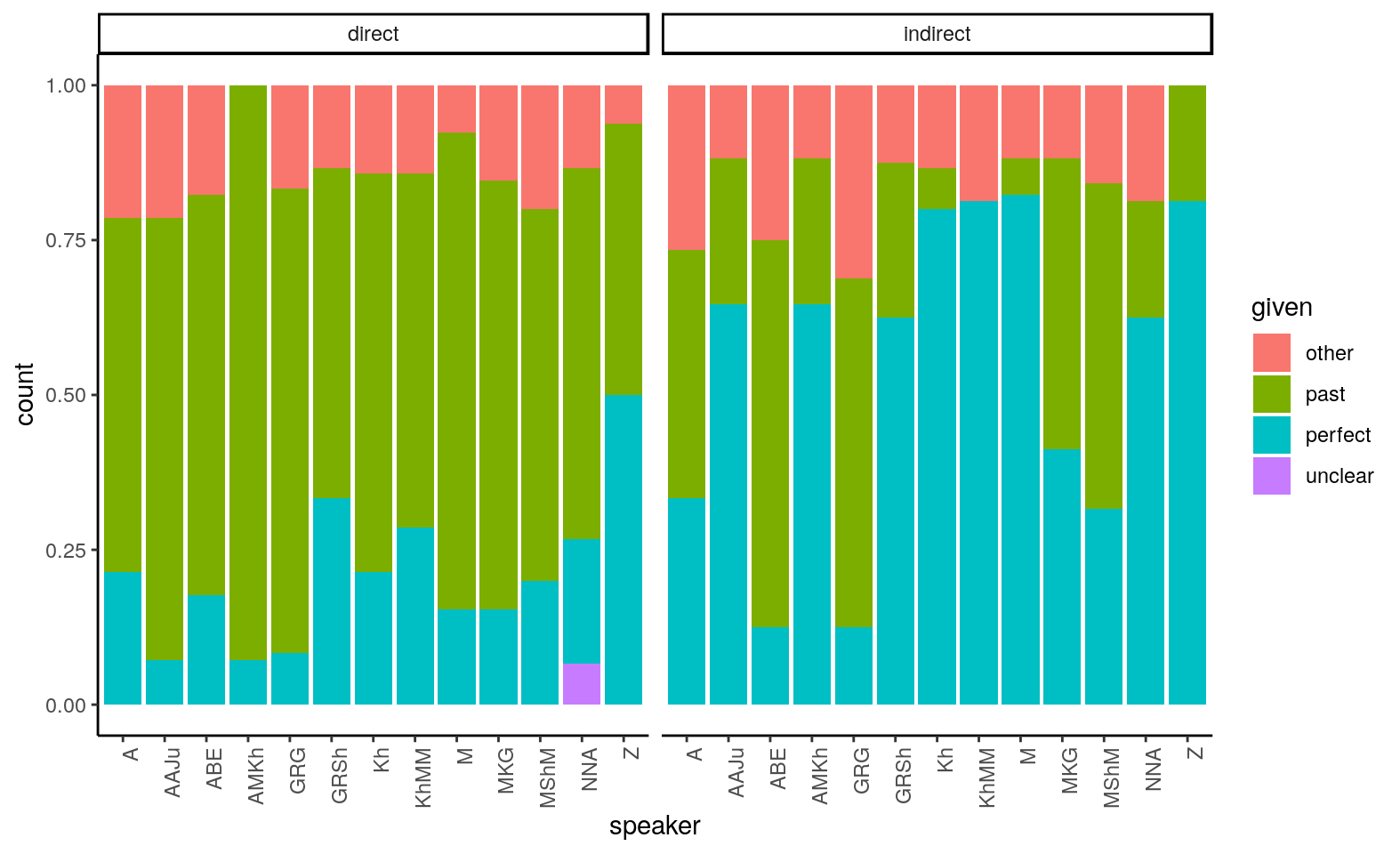
Распределение однако не сторогое: иногда появляются короткие цепочки перфектов в засвидетельствованном контексте для обозначения внезапных и неожиданных событий, а аорист может использоваться в заглазном контекстке в качестве нейтральной альтернативой. Рисунок ниже показывает долю разных используемых форм для каждого носителя и каждого контекста. Распределение форм показывает всего лишь тенденцию, а не строгое грамматическое правило.
Рисунок: Доля используемых форм в разных контекстах для каждого носителя
Нарративные данные
Настоящий раздел обсуждает употребление форм в не-элицитированных текстах, на основе материала, опубликуемого в грамматиках багвалинского и цахурского языков.
Багвалинский (андийский) и цахуский (лезгинский) языки относятся к разным ветвям нахско-дагестанской семьи, и на них говорят в разных регионах восточного Кавказа.
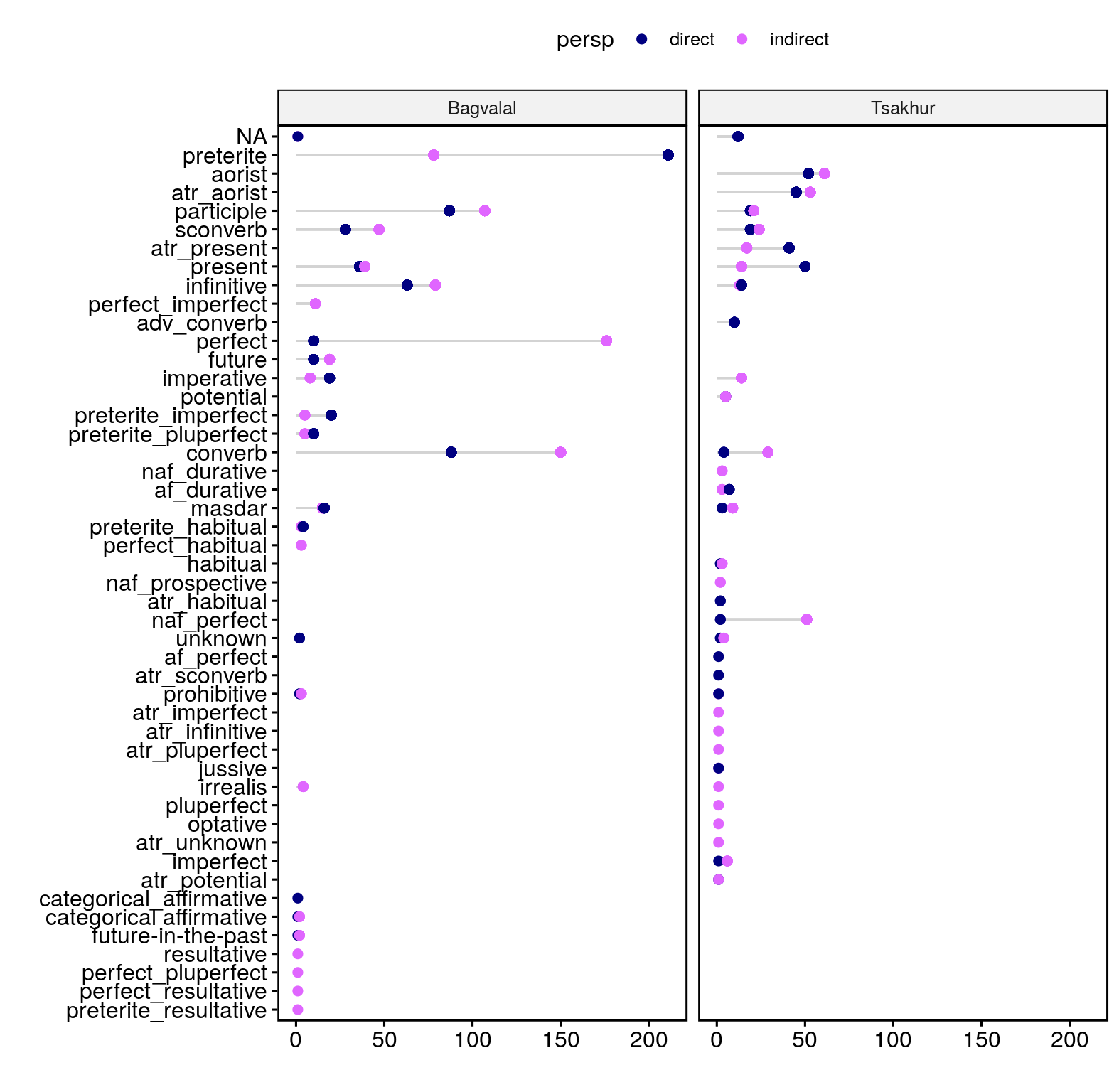
В целом данные показывают ту же тенденцию, что и элицитированные нарративы в андийском: общее прошедшее (претерит или аорист) и перфект – самые частотные финитные формы, и они выявляют предпочтение для определенной эвиденциальной перспективы (см. рисунок ниже).
Рисунок: Формы, используемые в разных контекстах в багвалинских и цахурских текстах
Теперь посмотрим распределение только двух основных финитных форм в нарративных цепочках, поскольку они образуют основную линию рассказа.
К сожалению, багвалинская и цахурская выборки – несбалансированы, и неравны друг другу (см. таблицу ниже). Носители почти исключительно мужчины, и речь некоторых из них перепредставлена по сравнению с другими. Это связано с тем, что материал был собран во время экспедиции в поле. В результате, в выборку попалаи только те носители, которые были готовы работать с лингвистами.
## # A tibble: 4 x 6
## # Groups: lang [2]
## lang sp_gender speakers sequences clauses av_length
## <chr> <chr> <int> <int> <int> <dbl>
## 1 Bagvalal f 2 6 150 25
## 2 Bagvalal m 8 43 1221 28.4
## 3 Tsakhur f 1 4 41 10.2
## 4 Tsakhur m 7 13 876 67.4Рисунок: перфекты и прошедшие в разных контекстах в багвалинских и цахурских текстах
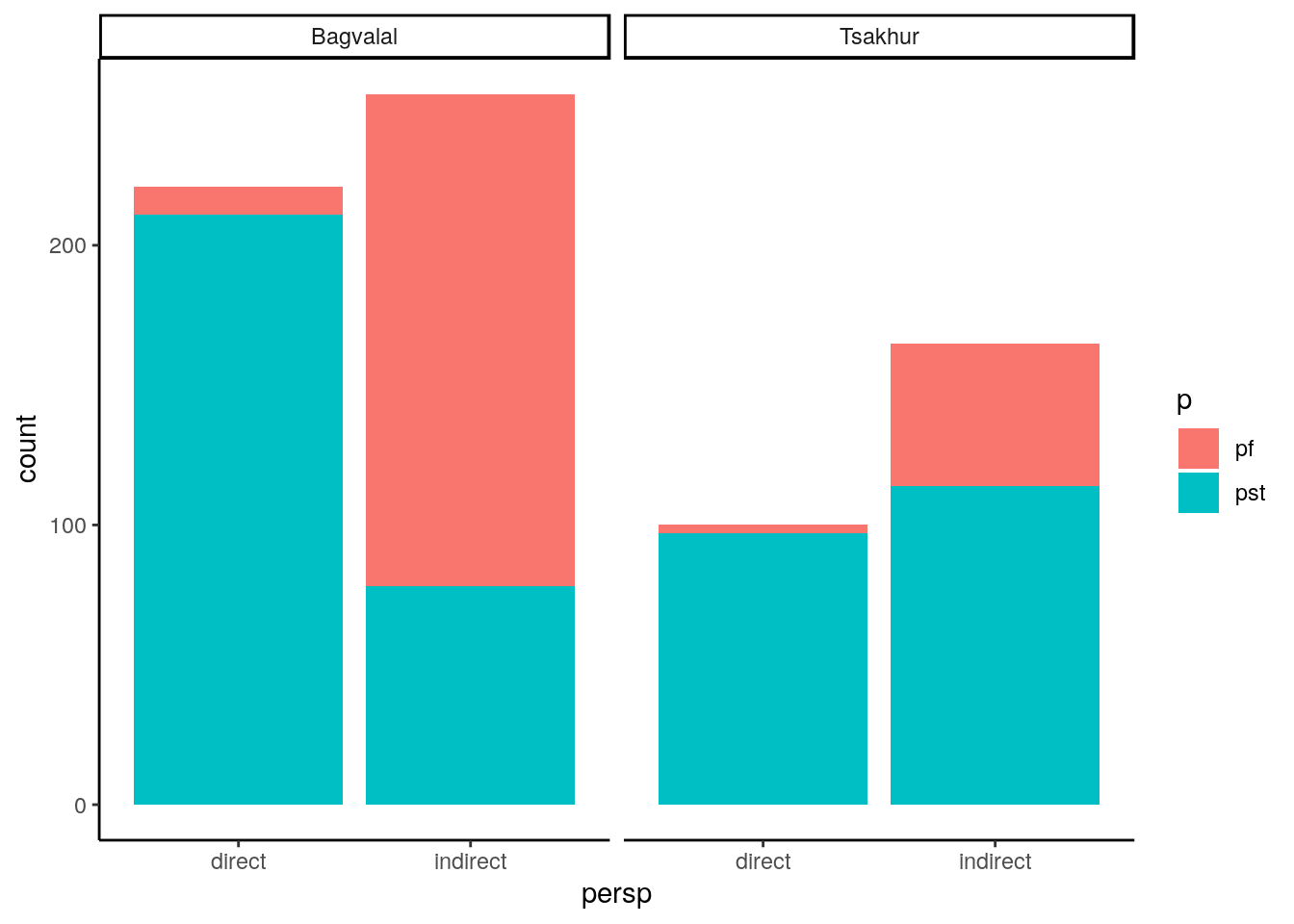
В обоих языках обнаруживается ассиметрию между перфектом и прошедшим в плане того, что прошедшее представляет собой более нейтральный, менее маркированный вариант оппозиции. При этом, у носителей багвалинского языка более сильное предпочтение для перфекта в заглазных контекстах. Стоит отметить, что этот эффект может быть результатом особенностей выборки, вместо грамматической разницы между этими языками.
В таблицах ниже можно увдеть абсолютные цифры, которые стоят за этими графами, также, как и результаты теста хи-квадрата, подтверждающего, что корреляция между перспективой и формой - статистически значима.
Багвалинский язык: статистическая значимость
##
## pf pst
## direct 10 211
## indirect 176 78##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: bagv$persp and bagv$p
## X-squared = 205.36, df = 1, p-value < 2.2e-16Цахурский язык: статистическая значимость
##
## pf pst
## direct 3 97
## indirect 51 114##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: tsakh$persp and tsakh$p
## X-squared = 28.196, df = 1, p-value = 1.096e-07Карты
Ниже – частичная репродукция карты 78A. Coding of Evidentiality (Haan 2013) из World Atlas of Language Structures (WALS) онлайн. На карте показаны только нахско-дагестанские языки. Наведите курсор на точки чтобы удиветь язык, который они представляют, и нажмите, чтобы показать ссылку на источник сведений о языке. Более подробную библиографическую информацию можно найти на сайте WALS.
Категория Part of the tense system (часть временной системы) содержит все языки с эвиденциальным перфектом и чеченский, в котором наличествует специализированный вспомогательный глагол для образования эвиденицальных временных форм. Mixed (смешанный) покрывает языки, которые сочетают временные формы с специализированными клитиками Verbal affix or clitic.
Карта: Эвиденциальность на восточном Кавказе (WALS)
Согасно нашим данным, отдельные языки получили другую классификацию чем на карте WALS (ср. наш issue по этому поводу на гитхабе).
Карта ниже учитывает больше языков, включая местные тюркские языки (азербайджанский, кумыкский, ногайский).
Карта: Эвиденциальность на восточном Кавказе (наши данные)
Обе карты показывают похожий ареальный паттерн: эвиденциальность как часть временной системы менее характерна для южной части региона.
Карта ниже показывает распределение категории эвиденциальности как часть временной системы, объединив категории Part of the tense system и Mixed предыдущей карты.
Карта: эвиденциальность как часть временной системы на восточном Кавказе
Следующая карта показывает, имеет ли перфект эвиденциальное значение.
Карта: перфекты с эвиденциальным значением на восточном Кавказе
Теперь посмотрим распределение эвиденциальной функции по сравнению с другими функциями перфекта.
Карта: функции перфектов на восточном Кавказе
Карта ниже сравнивает распределение категории эвиденицальность в видо-временной системе с распределением разного рода клитик: клитические глаголы, свободные частицы, и т.д. Распределение клитик не показывает сильный ареальный или генеалогический сигнал.
Карта: Эвиденциальность как часть временной системы и эвиденциальные клитики
Карты ниже показывают действительное распределение языков в регионе. Каждая точка соответствует одному населенному пункту. Нажмите на точку, чтобы показать название населенного пункта. Наведите курсор на точку, чтобы увидеть язык. Настоящая карта основана на старой версии датасета East Caucasian villages dataset (до обновления октября 2019 года) – самую последнюю версию можно скачать отсюда.
Карта: Все сёла на восточном Кавказе: языки
Следующая карта показывает наши данные по отношению к реальному распределению языков.
Карта: Все сёла на восточном Кавказе: языки + данные про эвиденциальность
Большинство точек верхнего слоя карты соответствуют множеству сёл. Каждое из этих сёл представляет собой уникальный идиом, который может отличаться от идиома из используемого источника. Эта проблема особенно остро стоит для определенных даргинских идиомов. К тому же, не все источники дают нам всю информацию, которая нам нужна – в связи с тем, что частицы и клитики не всегда описываются в подробностях, возможно многие красные точки на самом деле должны быть серыми. Неточность розовых и белых точек при этом менее вероятна, поскольку данные языки в этом плане достаточно изучены (за исключением табасаранского).
В результате, южная зона – достаточно надежное явление, которое более менее совпадает с регионом, где азербайджанский язык исторически был самым главным языков межъэтнического общения.
Карта ниже добавляет к сёлам и языкам исторически важные рынки и язык, на котором там говорили, согласно (1980).
Карта: Все сёла на восточном Кавказе: языки + рынки
Согласно нашим данным, в кумыкском и ногайском языках имеется эвиденциальный перфект, тогда как азербайджанский перфект утратил свою эвиденциальную функцию. Это совпадает с наблюдаемым нами распределением наличия эвиденциальности (в форме косвенной засвидетельствованности) в нахско-дагестанских перфектах. Однако, на данный момент нельзя сказать, что эвиденциальная функция нахско-дагестанских перфектов появилось под влиянием контакта с тюркскими народами, в связи с множеством факторов, описанных в нашей диссертационной работе и в статье, которая сейчас готовится к публикации.
Транскрипция
В таблице ниже сопоставлены транскрипция, используемая в наших данных (Current) по сранвнеию с конвенциями МФА (IPA) и транскрипцией, используемой в грамматиках цахурского (Tsakhur) и багвалинского (Bagvalal) языков.
Литература
Dahl, Östen. 2000. Tense and Aspect in the Languages of Europe. Berlin/New York: Mouton de Gruyter.
Ferxees, Samira. 2017. “Évidencial’nost’ I Perfekt V Rutul’skom Jazyke (Na Materiale Govora S. Kina) [Evidentiality and the Perfect in Rutul (Based on the Dialect of the Village Kina)].” In Élektronnaja Pis’mennost’ Narodov Rf: Opyt, Problemy I Perspektivy. Sbornik Materialov Naučnoj Konferencii, 16–17 Marta 2017g., Syktyvkar, edited by Marina Fedina, 228–35. Syktyvkar: KRAGSiU.
Forker, Diana. 2018. “Evidentiality in Nakh-Daghestanian Languages.” In The Oxford Handbook of Evidentiality, edited by Alexandra Y. Aikhenvald, 490–509. Oxford: Oxford University Press.
Haan, Ferdinand de. 2013. “Coding of Evidentiality.” In The World Atlas of Language Structures Online, edited by Matthew S. Dryer and Martin Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology. https://wals.info/chapter/78.
Kassambara, Alboukadel. 2018. Ggpubr: “Ggplot2” Based Publication Ready Plots. https://CRAN.R-project.org/package=ggpubr.
Moroz, George. 2017. Lingtypology: Easy Mapping for Linguistic Typology. https://CRAN.R-project.org/package=lingtypology.
RStudio Team. 2018. RStudio: Integrated Development Environment for R. Boston, MA: RStudio, Inc. http://www.rstudio.com/.
Wickham, Hadley. 2017. Tidyverse: Easily Install and Load the “Tidyverse”. https://CRAN.R-project.org/package=tidyverse.
Wixman, Ronald. 1980. Language Aspects of Ethnic Patterns and Processes in the North Caucasus. University of Chicago, Department of Geography.
Xie, Yihui, Joe Cheng, and Xianying Tan. 2019. DT: A Wrapper of the Javascript Library ’Datatables’. https://CRAN.R-project.org/package=DT.
“формы, похожие на перфект” достаточно мутное определение. Имеется в виду, что во всех языках семьи имеется форма со структурой, типичной для перфекта (т.е. она состоит из прошедшей или перфективной нефинтной формы + вспомогательного глагола настоящего времени), или форма, восходящая к такой структуре. При этом она имеет одно или больше значений, которые ассоциируются с перфектом: результатив (в узком смысле), перфект = текущая релевантность, и косвенная засвидетельствованность.↩
В цахурском языке этот вспомогательный глагол также является частью перфекта.↩
Есть разные версии анкеты для мужских и женских консультантов.↩
Вероятно в транскрипции множество неточностей.↩